1 文件浏览(简单回顾)
1 cat 查看文件的内容
2 more 以翻页的形式查看,但是只能向下翻页
3 less 以翻页的形式查看,但是能够支持向上和向下翻页
4 head 默认是查看前10行,但是我们指定查看的行数
5 tail 默认是查看后10行,但是我们可以指定查看的行数
2 基于关键字的搜索
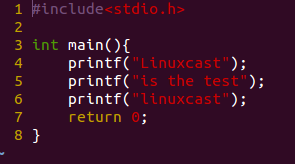
假设我在家目录下创建了一个tmp.cpp
1 命令grep是基于关键字进行搜索
2 单个关键字搜索: grep 关键字 文件名
比如我在tmp.cpp 里面搜索Linux

3 多关键字搜索: grep -E "关键字|关键字..." 文件名
比如我在tmp.cpp里面同时搜索哦含有Linux 和test

4 grep的其它参数
1 -i 是忽略大小写

2 -n 是显示结果所在的行
3 -v 是输出不带关键字的行(等于取反)
4 -Ax是输出的时候包含结果所在行之后x行
5 -Bx是输出的时候包含结果所在行之前x行
3 基于列的处理
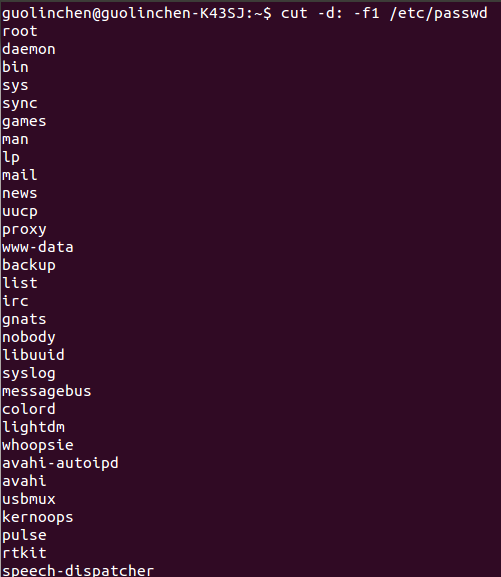
1 cut命令是用于基于列的文本处理
2 cut -dc -fx 文件名
c是要分割的字符(默认是TAB),x是显示第几列
比如我以":"作为分割符 查看/etc/passwad的第1列
2 我们也可以利用管道来进行cut
比如我先利用grep命令在/etc/passwad中搜索出含有chen关键字的文本结果,然后利用管道去cut出用:作为分割符并且显示第六列


4 文本统计
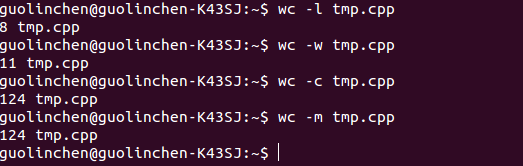
1 wc命令用来统计文本的信息,默认输出几行,几个单词,几个字节,文件名
我们还是利用上面的tmp.cpp

2 wc还有一些参数
-l 只统计行数
-w 只统计单词
-c 只统计字节数
-m 只统计字符数
5 文本排序
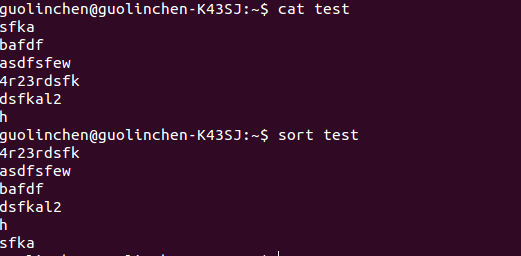
1 命令sort是用来对文本进行排序 sort 文本名
2 sort的常用的参数
-r 进行倒序排序
-n 基于数字进行排序
-r 忽略大小写
-u 删除重复行
-tc 使用c作为分割符分割为列进行排序
-kx 当基于分割符分割为列进行排序时,指定x列来排序
3 删除重复行
sort -u 文件名
uniq 文件名 用来删除相邻的重复行
6 文本的比较
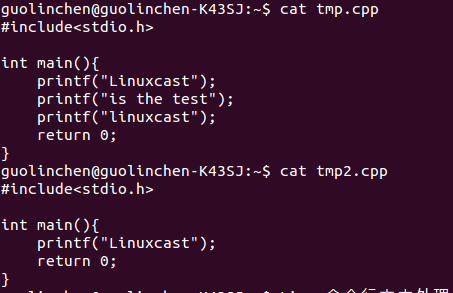
1 命令diff用来比较两个文本文件
diff 文件1 文件2
比如我们比较家目录下的tmp.cpp 和 tmp2.cpp

2 diff的一些参数
-i 忽略大小写
-b 忽略空格的数量
-u 统一的显示比较的信息,用以生成patch文件,一般可以用来作为补丁,实际上就是把比较信息重定向到patch文件

7 文本处理
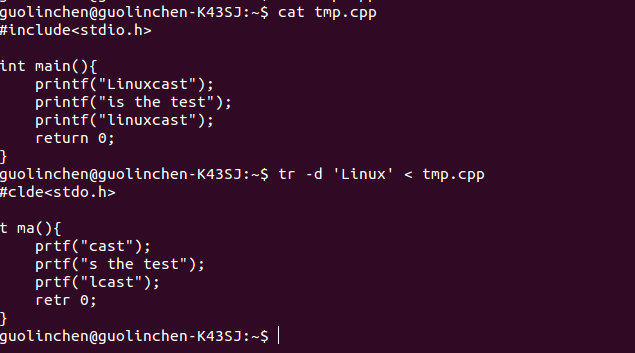
1 删除某个关键字
tr -d 关键字 < 文件名
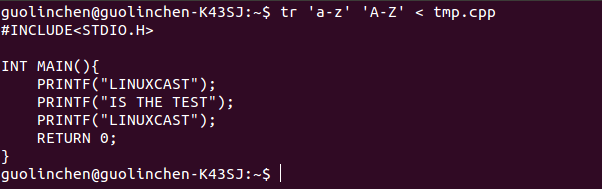
2 转换大小写
tr 'a-z' 'A-Z' < 文件名
7 文本的搜索替换
命令sed用来实现文本的替换功能,其内部实现的是一个正则表达式
1 sed 's/linux/unix/g' 文件名
那么这个命令就是把文本里面的linux替换为unix,g的意思是如果一行有多个linux则全部替换

2 sed '1,50s/linux/unix/g' 文件名
那么这个命令就是把1~50行里面的linux替换为unix,g的意思是如果一行有多个linux则全部替换
3 sed -e 's/linux/unix/g' -e 's/haha/fuck/g' 文件名
那么这个命令就是实现多个同时替换,把所有linux替换为unix,haha替换为fuck

4 sed -f sededit 文件名
这个命令就是说如果我们很厂用到某个命令,那么我们把这个命令写道sededit文本里面,那么每次调用-f sededit就比较方便